Oracle Clusterware has introduced a whole bunch of new features. One of the key features is the ability for DBA’s to add nodes without massive modification from DBA’s. This feature is based upon standard RAC concepts:
Each node has a virtual IP or VIP. VIP’s are assigned to each nodes. If a node becomes unavailable the VIP can be reassigned to another node.
You have an additional set of virtual IP’s called SCAN’s which are owned by the cluster. Scan’s all resolve to the same DNS name very similar to a DNS round robin (without the round robin). You have a Scan for each node. Clients connect to the cluster via the Scan IP addresses. If a node becomes unavailable the other nodes answer the scan requests.
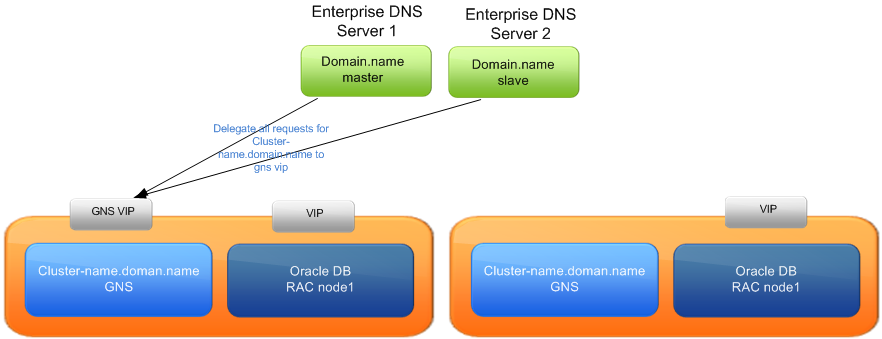
The cluster has a vip called GNS (Global Name Service) which is an DNS server for a subdomain where the cluster lives. The GNS runs on each node in the cluster and if the current active node becomes unavailable then the GNS vip is moved to another node.

This process is dependent upon DNS, DHCP and lots of IP addresses. The Oracle documentation is pretty weak on the systems details on this process and assumes that you will setup a dedicated DHCP and network for your RAC setup. Personally I like to have full control over my DHCP setup which has posed some unique problems.
DHCP Setup:
DHCP is a very basic protocol. A client sends out a layer 2 broadcaster with some potential options and waits for a DHCP server to respond. Normally a DHCP client send it’s MAC address as one of the options. Then the DHCP server responds with a layer 2 packet to the client identifying the clients IP address and additional options (such as router, domain name etc..) Since the SCAN’s and VIP’s need to be mobile it’s impossible to provide a MAC address without breaking the protocol. So it provides a generic mac (output from /var/log/messages):
DHCPDISCOVER from 00:00:00:00:00:00 via eth0
As you can see the client (a VIP in this case) is identifing it’s self as 00:00:00:00:00:00 which is an impossible mac address. So passing out addresses locked to specific mac address is not an option. Our friends at Oracle did provide another option the DHCP request does contain a dhcp-client-identifier which is unique to the DNS name for each requested address (node1-vip.cluster-name.domain.name etc..) This name if forgotten can be obtained by opening up the DHCP server and viewing the dhcpd.leases file. The dhcp-client-identifier can be located as uid inside the correct entry.
Once you have located the client identifier your ready to lock down your dhcp server using the class (used to define groups of clients based upon expressions)
If my client identifiers were “\000node1vip” and “\000node2vip” then my class in DHCP would look like (defined inside the subnet area):
class "oracle-vip-class" {
match if option dhcp-client-identifier = "\000node1vip" or
option dhcp-client-identifier = "\000node2vip";
}
We would then limit our range and assign it to vip’s using the following statement:
pool {
range 10.10.101.10 10.10.101.12;
allow members of "oracle-vip-class";
}
This does spit in the face of Oracle original intent. Now it requires a DHCP administrator to add a match statement before a node can aquire an vip or scan.
DNS Setup:
As shown above you need to have your enterprise DNS servers point to GNS Vip for a subdomain. This is a standard subdomain setup without many modifications. I found that I had to remove my forwarders line before it would work. Forcing my DNS server to query root servers instead of upstream DNS servers.



{kind=link}